publications
Publications are listed in reverse chronological order. * denotes equal contribution.
2026
- arXiv preprint
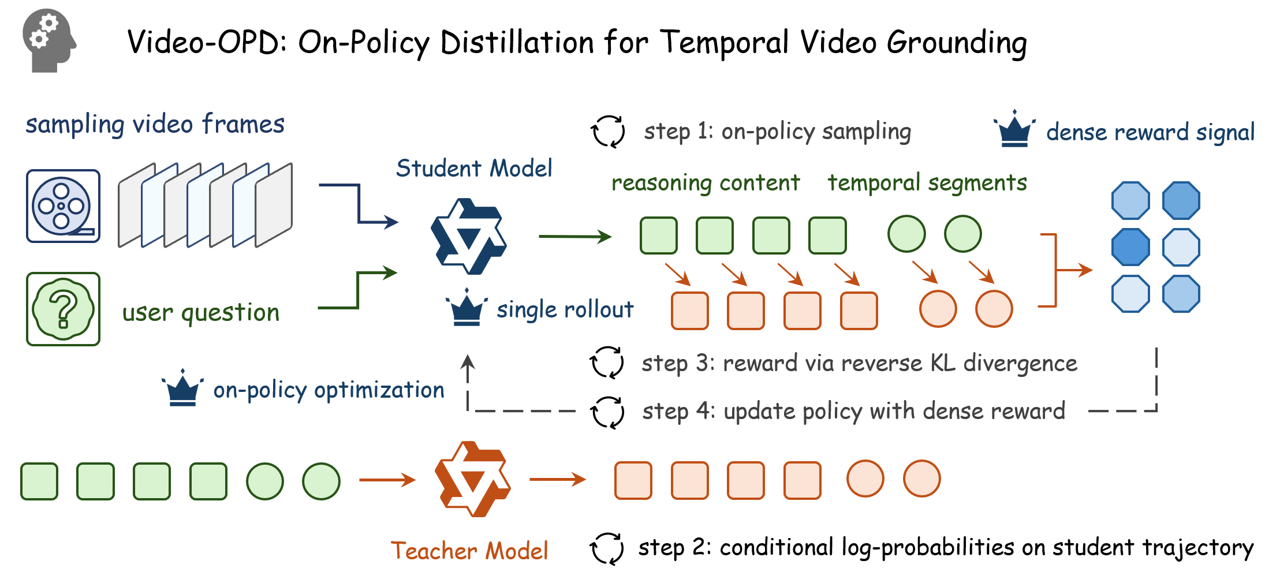 Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy DistillationJiaze Li*, Hao Yin*, Haoran Xu*, Boshen Xu, Wenhui Tan, and 4 more authorsIn arXiv preprint arXiv:2602.02994, Feb 2026
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy DistillationJiaze Li*, Hao Yin*, Haoran Xu*, Boshen Xu, Wenhui Tan, and 4 more authorsIn arXiv preprint arXiv:2602.02994, Feb 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
@inproceedings{li2026video, title = {Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation}, author = {Li, Jiaze and Yin, Hao and Xu, Haoran and Xu, Boshen and Tan, Wenhui and He, Zewen and Ju, Jianzhong and Luo, Zhenbo and Luan, Jian}, year = {2026}, month = feb, booktitle = {arXiv preprint arXiv:2602.02994}, } - CVPR 2026
 REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video UnderstandingJiaze Li*, Hao Yin*, Wenhui Tan*, Jingyang Chen*, Boshen Xu, and 5 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Feb 2026
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video UnderstandingJiaze Li*, Hao Yin*, Wenhui Tan*, Jingyang Chen*, Boshen Xu, and 5 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Feb 2026Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model’s reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
@inproceedings{li2025revisor, title = {REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding}, author = {Li, Jiaze and Yin, Hao and Tan, Wenhui and Chen, Jingyang and Xu, Boshen and Qu, Yuxun and Chen, Yijing and Ju, Jianzhong and Luo, Zhenbo and Luan, Jian}, year = {2026}, month = feb, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, }
2025
- NeurIPS 2025
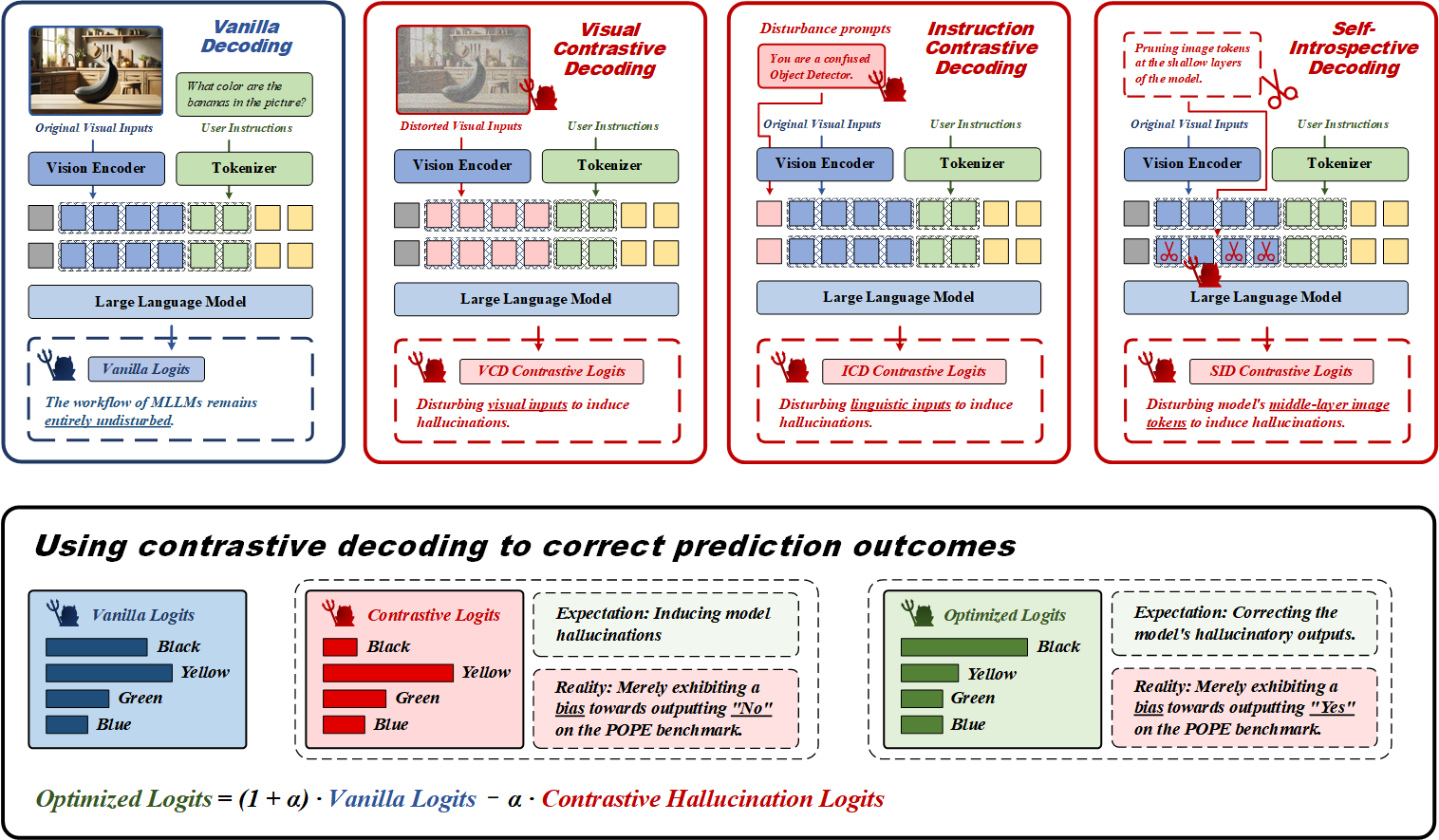 The Mirage of Performance Gains: Why Contrastive Decoding Fails to Mitigate Object Hallucinations in MLLMsHao Yin, Guangzong Si, and Zilei WangIn Advances in Neural Information Processing Systems, Dec 2025
The Mirage of Performance Gains: Why Contrastive Decoding Fails to Mitigate Object Hallucinations in MLLMsHao Yin, Guangzong Si, and Zilei WangIn Advances in Neural Information Processing Systems, Dec 2025Contrastive decoding strategies are widely used to reduce hallucinations in multimodal large language models (MLLMs). These methods work by constructing contrastive samples to induce hallucinations and then suppressing them in the output distribution. However, this paper demonstrates that such approaches fail to effectively mitigate the hallucination problem. The performance improvements observed on POPE Benchmark are largely driven by two misleading factors: (1) crude, unidirectional adjustments to the model’s output distribution and (2) the adaptive plausibility constraint, which reduces the sampling strategy to greedy search. To further illustrate these issues, we introduce a series of spurious improvement methods and evaluate their performance against contrastive decoding techniques. Experimental results reveal that the observed performance gains in contrastive decoding are entirely unrelated to its intended goal of mitigating hallucinations. Our findings challenge common assumptions about the effectiveness of contrastive decoding strategies and pave the way for developing genuinely effective solutions to hallucinations in MLLMs.
@inproceedings{yin2025mirageperformancegainscontrastive, title = {The Mirage of Performance Gains: Why Contrastive Decoding Fails to Mitigate Object Hallucinations in MLLMs}, author = {Yin, Hao and Si, Guangzong and Wang, Zilei}, year = {2025}, month = dec, booktitle = {Advances in Neural Information Processing Systems}, } - CVPR 2025
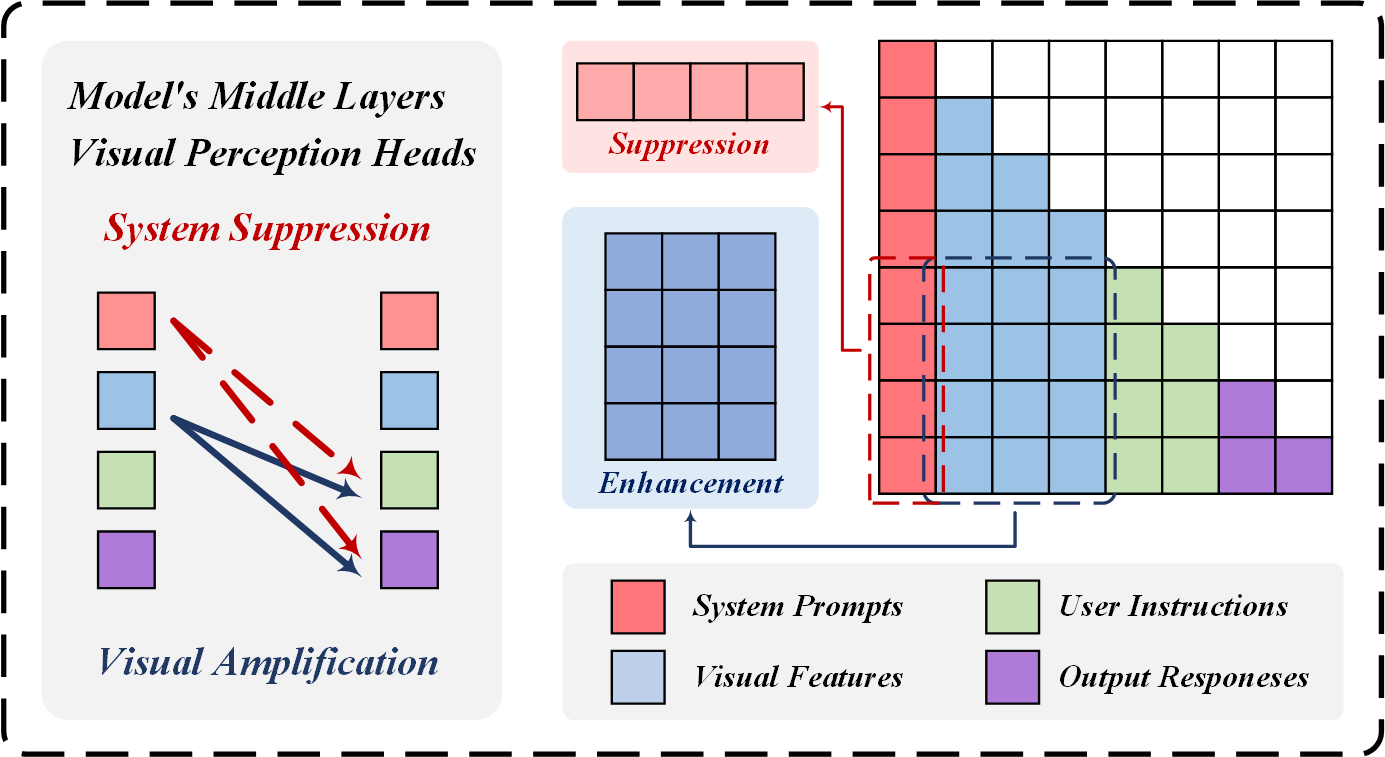 ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language ModelsHao Yin, Guangzong Si, and Zilei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2025
ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language ModelsHao Yin, Guangzong Si, and Zilei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2025Contrastive decoding strategies are widely used to mitigate object hallucinations in multimodal large language models (MLLMs). By reducing over-reliance on language priors, these strategies ensure that generated content remains closely grounded in visual inputs, producing contextually accurate outputs. Since contrastive decoding requires no additional training or external tools, it offers both computational efficiency and versatility, making it highly attractive. However, these methods present two main limitations: (1) bluntly suppressing language priors can compromise coherence and accuracy of generated content, and (2) processing contrastive inputs adds computational load, significantly slowing inference speed. To address these challenges, we propose Visual Amplification Fusion (VAF), a plug-and-play technique that enhances attention to visual signals within the model’s middle layers, where modality fusion predominantly occurs. This approach enables more effective capture of visual features, reducing the model’s bias toward language modality. Experimental results demonstrate that VAF significantly reduces hallucinations across various MLLMs without affecting inference speed, while maintaining coherence and accuracy in generated outputs.
@inproceedings{yin2025clearsightvisualsignalenhancement, title = {ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language Models}, author = {Yin, Hao and Si, Guangzong and Wang, Zilei}, year = {2025}, month = jun, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, } - CVPR 2025
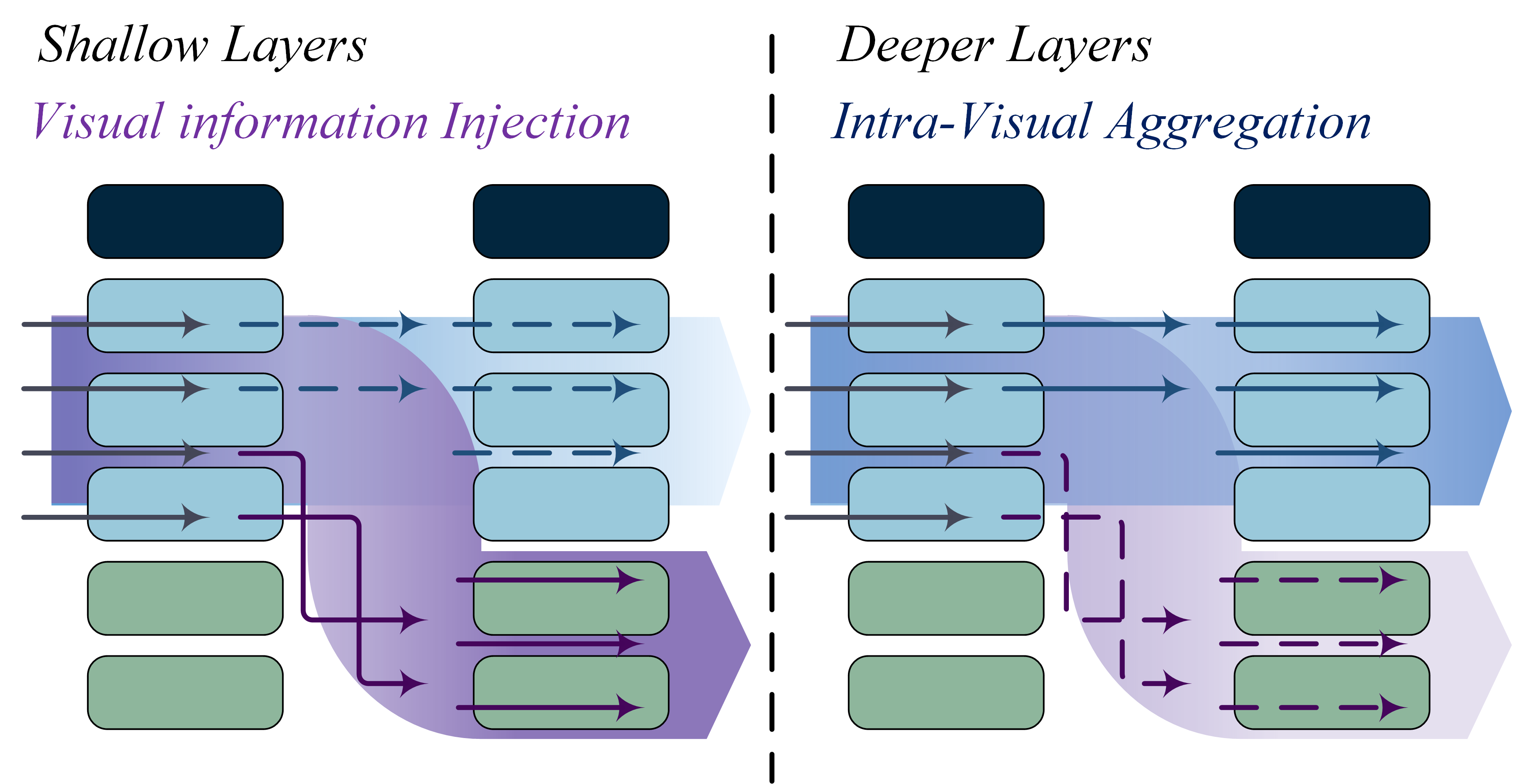 Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster InferenceHao Yin, Guangzong Si, and Zilei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2025
Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster InferenceHao Yin, Guangzong Si, and Zilei WangIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2025Multimodal large language models (MLLMs) improve performance on vision-language tasks by integrating visual features from pre-trained vision encoders into large language models (LLMs). However, how MLLMs process and utilize visual information remains unclear. In this paper, a shift in the dominant flow of visual information is uncovered: (1) in shallow layers, strong interactions are observed between image tokens and instruction tokens, where most visual information is injected into instruction tokens to form cross-modal semantic representations; (2) in deeper layers, image tokens primarily interact with each other, aggregating the remaining visual information to optimize semantic representations within visual modality. Based on these insights, we propose Hierarchical Modality-Aware Pruning (HiMAP), a plug-and-play inference acceleration method that dynamically prunes image tokens at specific layers, reducing computational costs by approximately 65% without sacrificing performance. Our findings offer a new understanding of visual information processing in MLLMs and provide a state-of-the-art solution for efficient inference.
@inproceedings{yin2025liftingveilvisualinformation, title = {Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster Inference}, author = {Yin, Hao and Si, Guangzong and Wang, Zilei}, year = {2025}, month = jun, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, }