Hao Yin (殷皓)
Actively looking for research internships in the United States
Master’s Student,
Artificial Intelligence & Data Science,
University of Science and Technology of China (USTC).
Research: My research is primarily focused on multimodal large language models, with an emphasis on enhancing their efficiency and robustness. Specifically, I investigate methods for accelerating inference by pruning redundant tokens based on the internal patterns of information flow within MLLMs. I also explore architectural and algorithmic improvements, such as refined attention mechanisms and sampling strategies, to reduce object hallucination and improve grounding in visual inputs. Broadly, my work aims to develop generalizable methodologies for building more effective and reliable multimodal AI systems.
Background: I am currently pursuing my Master’s degree in Artificial Intelligence & Data Science at the University of Science and Technology of China, advised by Zilei Wang in the Vision and Multimedia Research Group. I received my Bachelor’s degree in Mathematics and Applied Mathematics from China University of Mining and Technology, where I worked with Hu Shao.
news
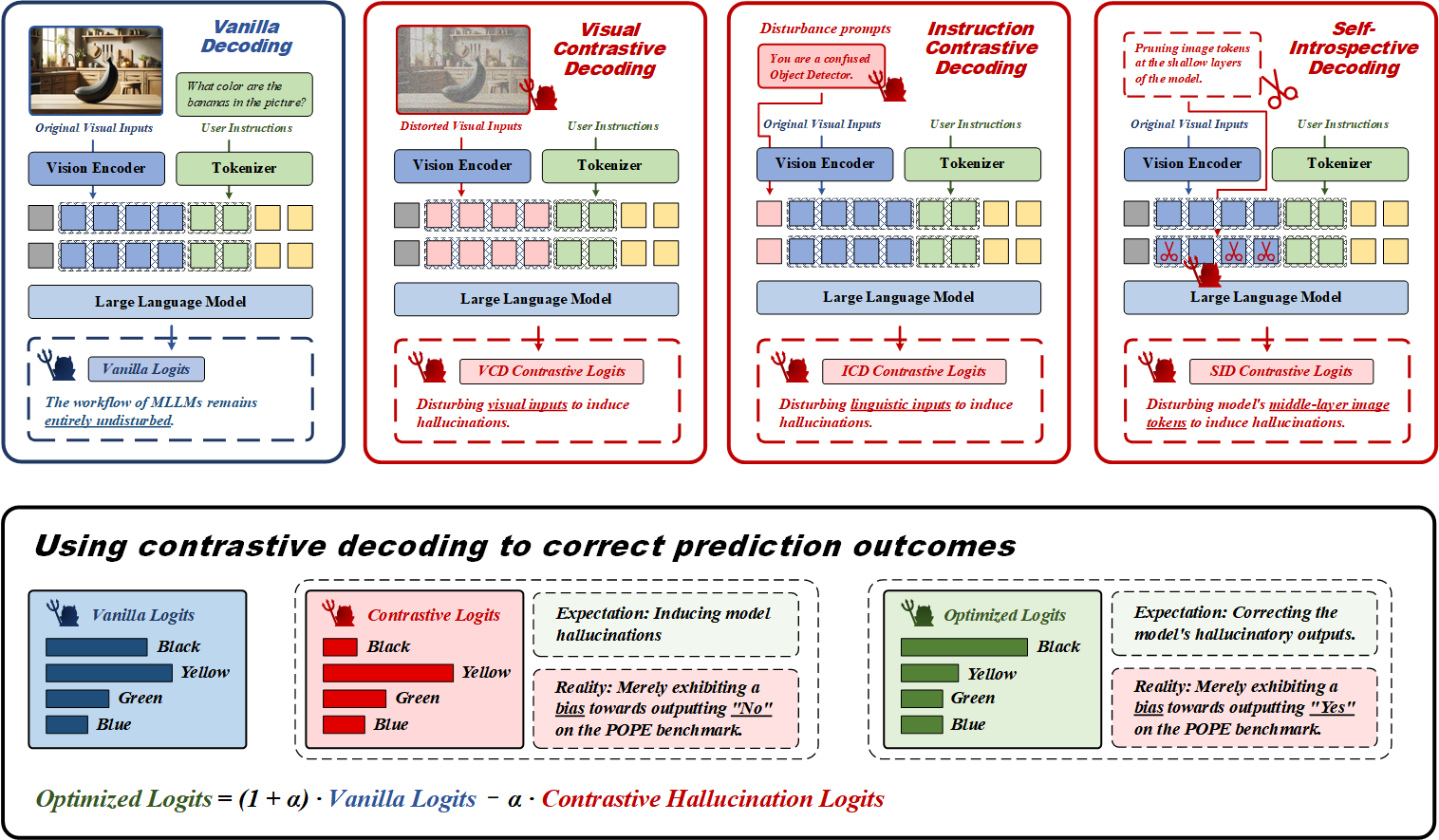
| Oct 7, 2025 | Our paper The Mirage of Performance Gains: Why Contrastive Decoding Fails to Mitigate Object Hallucinations in MLLMs? has been accepted to NeurIPS 2025! This work reveals that contrastive decoding fails to genuinely mitigate hallucinations. Any apparent improvements are merely artifacts of confounding factors, not true effectiveness. |
|---|---|
| Sep 15, 2025 | Excited to share that I’ve begun a research internship at Tencent! My project will involve exploring how to boost the common sense reasoning abilities of MLLMs. This will primarily be achieved through post-training approaches, focusing on efficient data construction and innovative training strategy design. |
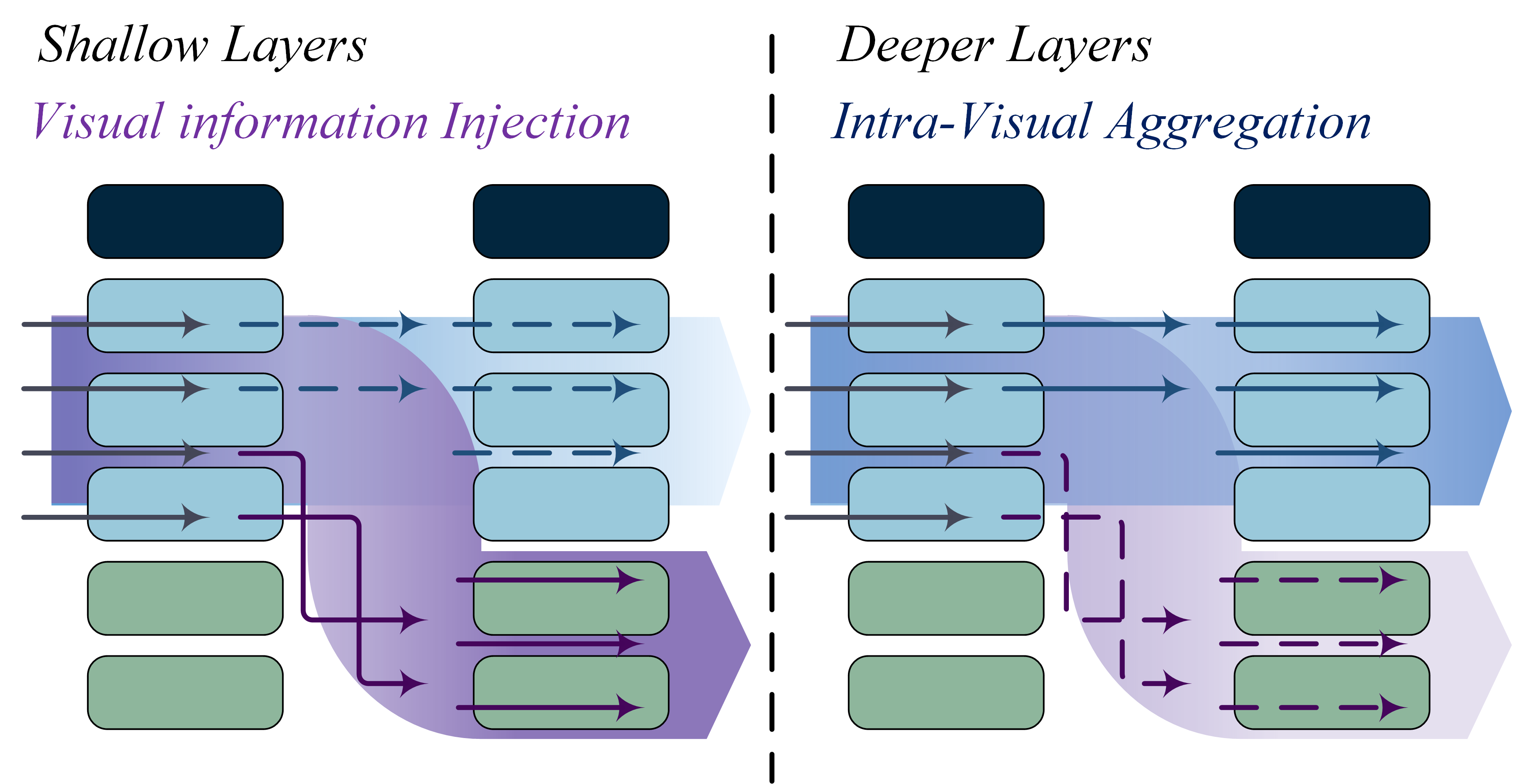
| Feb 28, 2025 | Our paper Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster Inference has been accepted to CVPR 2025! This work investigates the internal visual information flow patterns in MLLMs and proposes a novel training-free inference acceleration method based on our findings. |
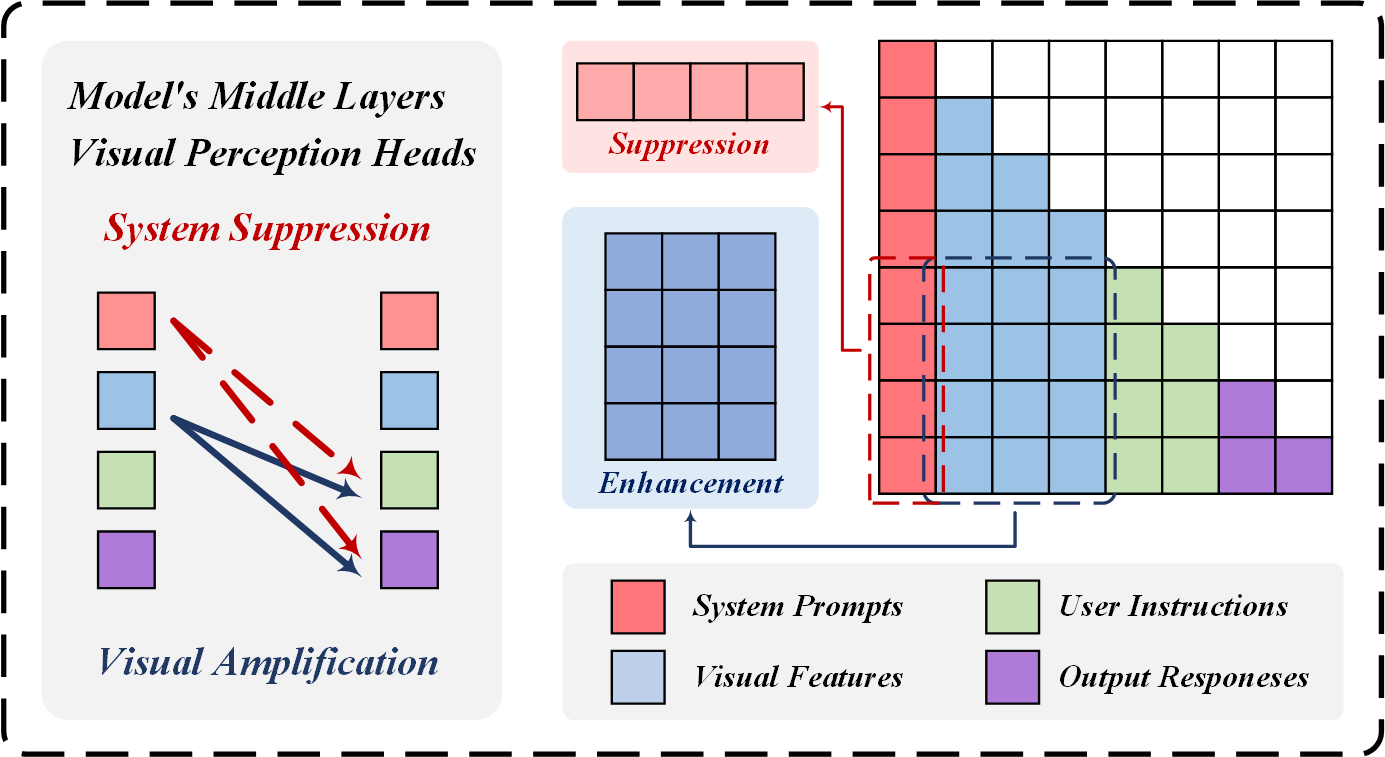
| Feb 28, 2025 | Our paper ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large Language Models has been accepted to CVPR 2025! In this work, we present a method to mitigate object hallucination in MLLMs by strengthening attention to visual input. |